AlphaDDA: strategies for adjusting the playing strength of a fully
Por um escritor misterioso
Last updated 08 novembro 2024
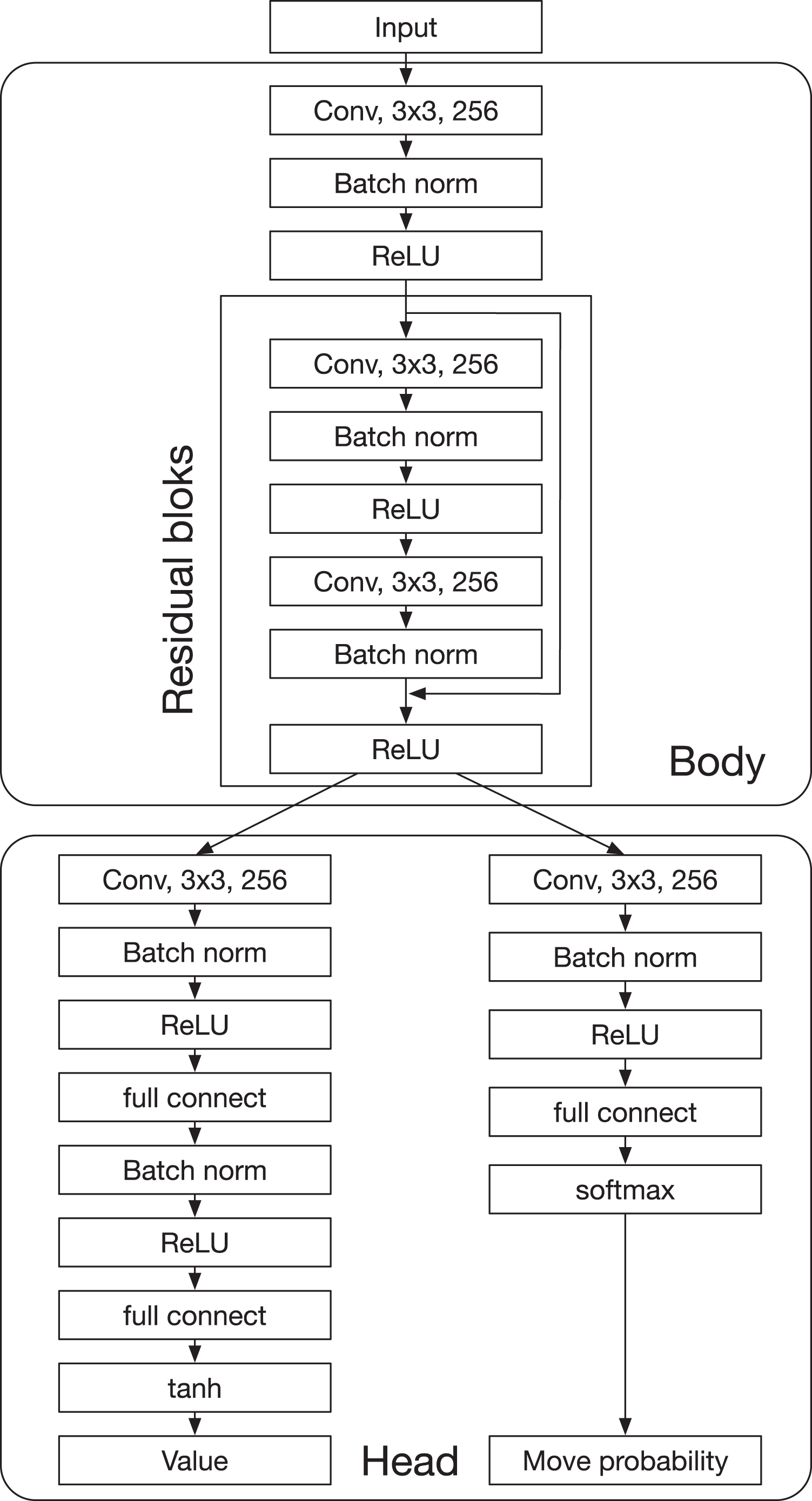
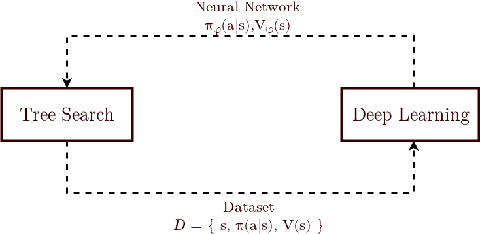
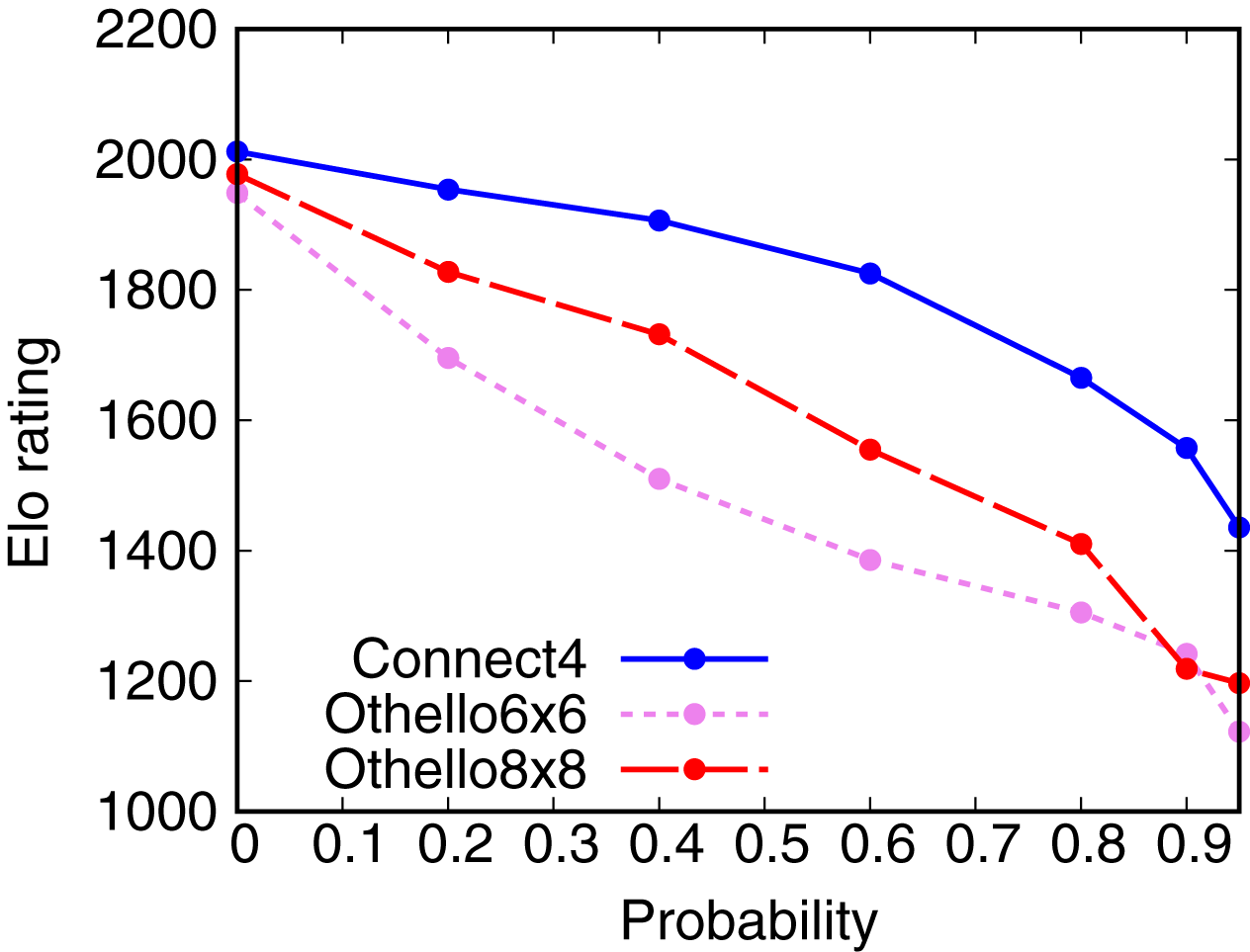
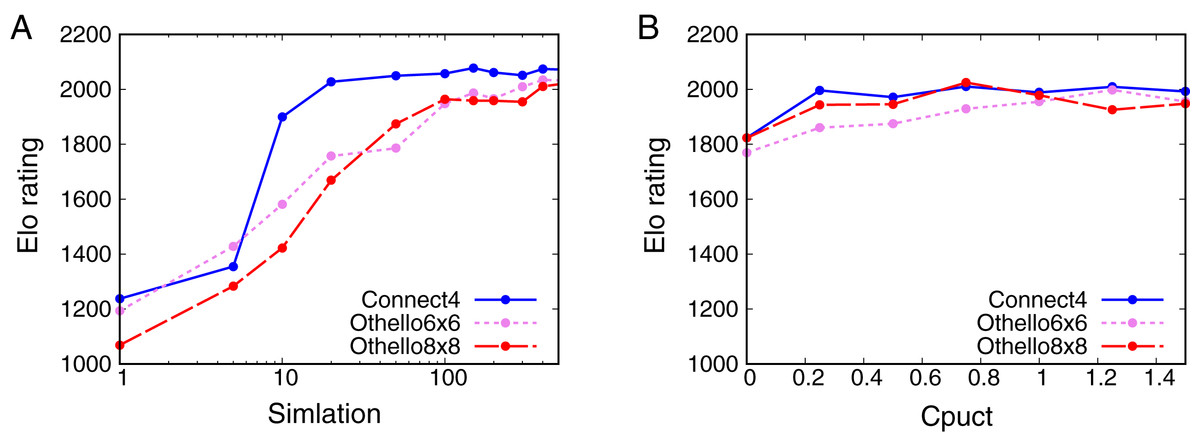
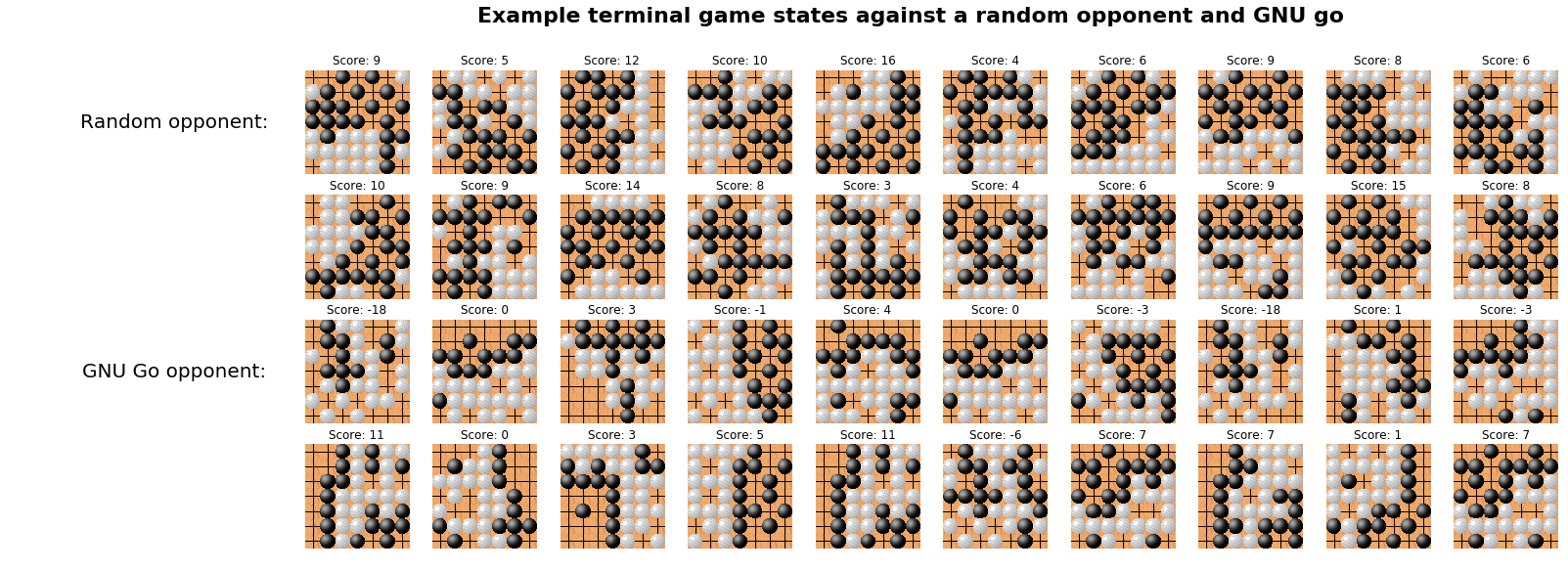
Artificial intelligence (AI) has achieved superhuman performance in board games such as Go, chess, and Othello (Reversi). In other words, the AI system surpasses the level of a strong human expert player in such games. In this context, it is difficult for a human player to enjoy playing the games with the AI. To keep human players entertained and immersed in a game, the AI is required to dynamically balance its skill with that of the human player. To address this issue, we propose AlphaDDA, an AlphaZero-based AI with dynamic difficulty adjustment (DDA). AlphaDDA consists of a deep neural network (DNN) and a Monte Carlo tree search, as in AlphaZero. AlphaDDA learns and plays a game the same way as AlphaZero, but can change its skills. AlphaDDA estimates the value of the game state from only the board state using the DNN. AlphaDDA changes a parameter dominantly controlling its skills according to the estimated value. Consequently, AlphaDDA adjusts its skills according to a game state. AlphaDDA can adjust its skill using only the state of a game without any prior knowledge regarding an opponent. In this study, AlphaDDA plays Connect4, Othello, and 6x6 Othello with other AI agents. Other AI agents are AlphaZero, Monte Carlo tree search, the minimax algorithm, and a random player. This study shows that AlphaDDA can balance its skill with that of the other AI agents, except for a random player. AlphaDDA can weaken itself according to the estimated value. However, AlphaDDA beats the random player because AlphaDDA is stronger than a random player even if AlphaDDA weakens itself to the limit. The DDA ability of AlphaDDA is based on an accurate estimation of the value from the state of a game. We believe that the AlphaDDA approach for DDA can be used for any game AI system if the DNN can accurately estimate the value of the game state and we know a parameter controlling the skills of the AI system.

Alpha generation: A Guide to Portable Alpha Strategies - FasterCapital

AlphaZero for a Non-Deterministic Game
FLD Trading Strategy (Advanced) - by David F - Sigma-L
PDF] A0C: Alpha Zero in Continuous Action Space
Mastering the Card Game of Jaipur Through Zero-Knowledge Self-Play Reinforcement Learning and Action Masks
Mastering the Card Game of Jaipur Through Zero-Knowledge Self-Play Reinforcement Learning and Action Masks
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]

Game Changer: AlphaZero's Groundbreaking Chess Strategies and the Promise of AI

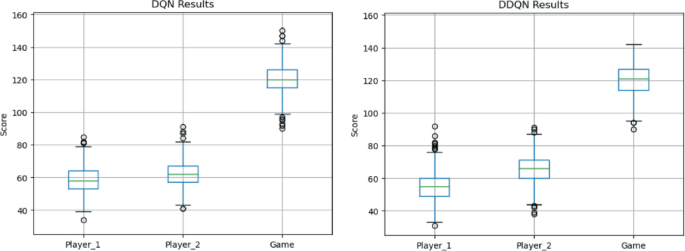
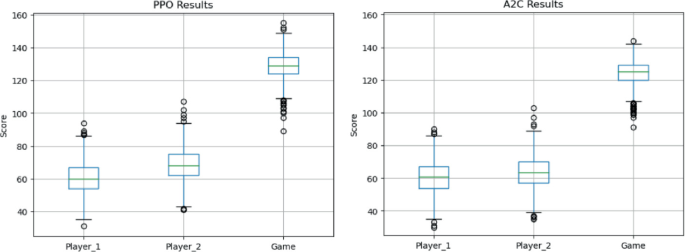
Average score in each game. DDA was active only in games 2 and 4.

PDF] Multiplayer AlphaZero

Game Changer: AlphaZero's Groundbreaking Chess Strategies and the Promise of AI
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]

arxiv-sanity
Recomendado para você
-
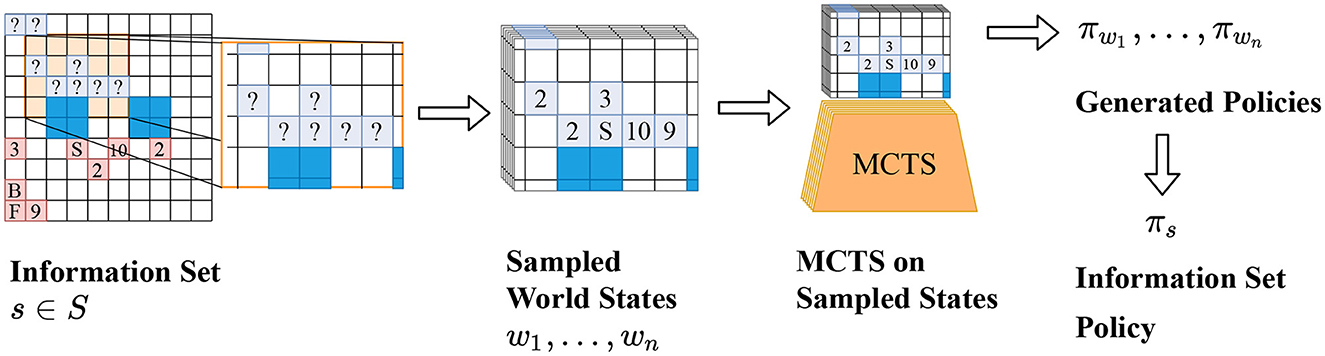 Frontiers AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong08 novembro 2024
Frontiers AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong08 novembro 2024 -
 🔵 AlphaZero Plays Connect 408 novembro 2024
🔵 AlphaZero Plays Connect 408 novembro 2024 -
 GitHub - junxiaosong/AlphaZero_Gomoku: An implementation of the08 novembro 2024
GitHub - junxiaosong/AlphaZero_Gomoku: An implementation of the08 novembro 2024 -
 Google跑不到谱· Issue #30 · NeymarL/ChineseChess-AlphaZero · GitHub08 novembro 2024
Google跑不到谱· Issue #30 · NeymarL/ChineseChess-AlphaZero · GitHub08 novembro 2024 -
 GitHub - CogitoNTNU/AlphaZero: An implementation of AlphaZero08 novembro 2024
GitHub - CogitoNTNU/AlphaZero: An implementation of AlphaZero08 novembro 2024 -
 AlphaZero implementation and tutorial, by Darin Straus08 novembro 2024
AlphaZero implementation and tutorial, by Darin Straus08 novembro 2024 -
 PDF) Tackling Morpion Solitaire with AlphaZero-likeRanked Reward08 novembro 2024
PDF) Tackling Morpion Solitaire with AlphaZero-likeRanked Reward08 novembro 2024 -
 Trend Micro sets up 2018 global AI contest inside company08 novembro 2024
Trend Micro sets up 2018 global AI contest inside company08 novembro 2024 -
 A general reinforcement learning algorithm that masters chess08 novembro 2024
A general reinforcement learning algorithm that masters chess08 novembro 2024 -
 What is Q*? And when we will hear more? - Community - OpenAI08 novembro 2024
What is Q*? And when we will hear more? - Community - OpenAI08 novembro 2024
você pode gostar
-
 Lord X Wrath/Listlessness, Funkipedia Mods Wiki08 novembro 2024
Lord X Wrath/Listlessness, Funkipedia Mods Wiki08 novembro 2024 -
 These could be the first screenshots from the PC version of Bloodborne08 novembro 2024
These could be the first screenshots from the PC version of Bloodborne08 novembro 2024 -
 Start Survey? Yes or No!08 novembro 2024
Start Survey? Yes or No!08 novembro 2024 -
 10 Video Games You Constantly Have To Defend Loving – Page 908 novembro 2024
10 Video Games You Constantly Have To Defend Loving – Page 908 novembro 2024 -
 Juegos Panamericanos y ParaPanamericanos Santiago 2023 – Chubut Deportes08 novembro 2024
Juegos Panamericanos y ParaPanamericanos Santiago 2023 – Chubut Deportes08 novembro 2024 -
 Live-A-Live Remake vs Original Early Graphics Comparison08 novembro 2024
Live-A-Live Remake vs Original Early Graphics Comparison08 novembro 2024 -
 Como Resgatar PromoCode do Roblox pelo Celular 202308 novembro 2024
Como Resgatar PromoCode do Roblox pelo Celular 202308 novembro 2024 -
 Cross Road Blues (Crossroads) by Robert Johnson - Piano, Vocal, Guitar - Digital Sheet Music08 novembro 2024
Cross Road Blues (Crossroads) by Robert Johnson - Piano, Vocal, Guitar - Digital Sheet Music08 novembro 2024 -
 Angry Cat Emoji Sticker for Sale by rkbubble08 novembro 2024
Angry Cat Emoji Sticker for Sale by rkbubble08 novembro 2024 -
 Diner Dash Adventures in 202308 novembro 2024
Diner Dash Adventures in 202308 novembro 2024